記事が見づらいなどの問題がありましたらContactからお知らせください。
FXデータ分析の練習(1)〜データの取得編〜
投稿日:2019年11月12日
pandasはデータ分析に非常に便利なライブラリです。この記事のシリーズではpandasを使ってFXのデータを分析する練習をしてみました。
練習
ライブラリのインストール
$ pip install pandas matplotlib jupyter[notebook] scipyサンプルデータの取得
HistData.comで過去の外貨のデータが取得できます。今回はこのサイトのEURUSDのデータを使ってデータ分析の練習をしてみます。以下の2つのリンクからデータのZipファイルを取得してきましょう。以下のリンク先の『Download Historical Data Here』からダウンロードできます。
- https://www.histdata.com/download-free-forex-historical-data/?/metatrader/1-minute-bar-quotes/eurusd/2018
- https://www.histdata.com/download-free-forex-historical-data/?/metatrader/1-minute-bar-quotes/eurusd/2017
ZIPファイルがダウンロードできたら、作業ディレクトリからアクセスできる場所に解凍しましょう。今回は直下に解凍しました。
ディレクトリの構成
ー
├── HISTDATA_COM_MT_EURUSD_M12017
│ ├── DAT_MT_EURUSD_M1_2017.csv
│ └── DAT_MT_EURUSD_M1_2017.txt
├── HISTDATA_COM_MT_EURUSD_M12018
├── DAT_MT_EURUSD_M1_2018.csv
└── DAT_MT_EURUSD_M1_2018.txtデータを読み込んで表示
JupyterNotebookでCSVデータを読み込んで表示してみます。
まずはライブラリのインポートから
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt次にCSVファイルを読み込みます。データにはヘッダの行がないのでname引数でヘッダを指定してあげます。データのパスは各個人が解答した相対パスを入れてください。
data1 = pd.read_csv(
"./HISTDATA_COM_MT_EURUSD_M12017/DAT_MT_EURUSD_M1_2017.csv",
names=["date","time","open","high","low","close","spread"])
data2 = pd.read_csv(
"./HISTDATA_COM_MT_EURUSD_M12018/DAT_MT_EURUSD_M1_2018.csv",
names=["date","time","open","high","low","close","spread"])
data1date time open high low close spread
0 2017.01.02 02:00 1.05155 1.05197 1.05155 1.05190 0
1 2017.01.02 02:01 1.05209 1.05209 1.05177 1.05179 0
2 2017.01.02 02:02 1.05177 1.05198 1.05177 1.05178 0
3 2017.01.02 02:03 1.05188 1.05200 1.05188 1.05200 0
4 2017.01.02 02:04 1.05196 1.05204 1.05196 1.05203 0
... ... ... ... ... ... ... ...
371630 2017.12.29 16:53 1.19972 1.19987 1.19972 1.19987 0
371631 2017.12.29 16:54 1.19985 1.19985 1.19970 1.19970 0
371632 2017.12.29 16:55 1.19969 1.20014 1.19961 1.20010 0
371633 2017.12.29 16:56 1.20009 1.20023 1.19974 1.19983 0
371634 2017.12.29 16:57 1.19982 1.20074 1.19980 1.20005 0
[371635 rows x 7 columns]このままだと日にちと時間がわかれていて使いづらいので、新しくdatetimeという日にちと時間がまとまった列を作成してみましょう。
特定のデータは辞書型の様にカラム名でアクセスできます。
カラム名でアクセスすることでそのカラムのすべての行のデータに対して同じ計算をすることができます。
data1["datetime"] = data1["date"] +"." + data1["time"]
data2["datetime"] = data2["date"] +"." + data2["time"]
data1date time open high low close spread \
0 2017.01.02 02:00 1.05155 1.05197 1.05155 1.05190 0
1 2017.01.02 02:01 1.05209 1.05209 1.05177 1.05179 0
2 2017.01.02 02:02 1.05177 1.05198 1.05177 1.05178 0
3 2017.01.02 02:03 1.05188 1.05200 1.05188 1.05200 0
4 2017.01.02 02:04 1.05196 1.05204 1.05196 1.05203 0
... ... ... ... ... ... ... ...
371630 2017.12.29 16:53 1.19972 1.19987 1.19972 1.19987 0
371631 2017.12.29 16:54 1.19985 1.19985 1.19970 1.19970 0
371632 2017.12.29 16:55 1.19969 1.20014 1.19961 1.20010 0
371633 2017.12.29 16:56 1.20009 1.20023 1.19974 1.19983 0
371634 2017.12.29 16:57 1.19982 1.20074 1.19980 1.20005 0
datetime
0 2017.01.02.02:00
1 2017.01.02.02:01
2 2017.01.02.02:02
3 2017.01.02.02:03
4 2017.01.02.02:04
... ...
371630 2017.12.29.16:53
371631 2017.12.29.16:54
371632 2017.12.29.16:55
371633 2017.12.29.16:56
371634 2017.12.29.16:57data1のopenをグラグ表示してみます。またpandasのDataFrameはplot()メソッドで簡単にグラフをプロットできます。
data1["open"].plot()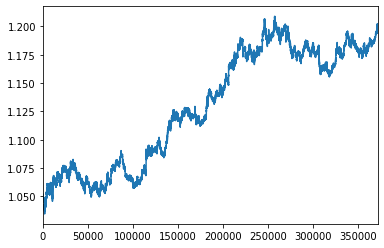
2017年のデータと2018年のデータを結合してみます。データの結合はconcat()メソッドで行うことができます。今回の様にindexがかぶっている2つのデータを結合させる場合、indexが重複してしまいます。indexを振り直すには引数でignore_index=Trueをわたすことで行えます。
ちなみに今度はグラフの見た目を少し変えてみました。グラフの色はplot()メソッドの引数で、ラベルはplt.ylabel()とplt.xlabel()で変更できます。
data_concated = pd.concat([data1,data2]).set_index("datetime")
data_concated["open"].plot(color="red")
plt.ylabel("EURUSD")
plt.xlabel("DATETIME")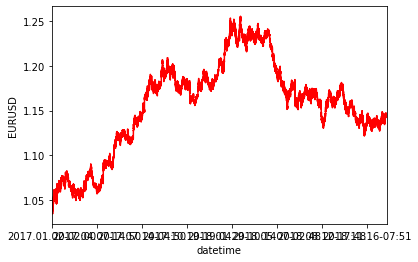
-
2019年12月7日【初心者チュートリアル】Django2でブログ作成(Part15)〜Pagination~
-
2019年11月26日【初心者チュートリアル】Django2でブログ作成(Part14)〜ページのデザイン~Djangoは簡単にWebアプリケーションを作成できるフレームワークです。この記事は初心…
-
2019年11月11日【初心者チュートリアル】Django2でブログ作成(Part7)〜ModelManager~Djangoは簡単にWebアプリケーションを作成できるフレームワークです。この記事は初心…
-
2020年1月16日Django2:ログのローテーションの方法について解説pythonではloggingモジュールの設定を適切に行うことで、簡単にログのローテーシ…
-
2019年9月4日pythonでファイルのメディアタイプを取得する方法解説メディアタイプはコンテンツがどのような種類のデータであるかを伝えるためのもので、Cont…
-
2020年11月16日【Python3】PyMySqlを使ってMySQLを操作(基礎・使用例)PyMySQLはMySQLをPythonから操作するクライアントライブラリの一つです。こ…